



 产品分类
产品分类
比传统方案功耗降低60%PCI Express缓冲器
 318
318
 拍明
拍明
相关元件供应
型号:SI53115-A01AGM 品牌:SILICON LABS
The Si53115 is a 15-output, low-power HCSL differential clock buffer thatmeets all of the performance requirements of the Intel DB1200ZLspecification. The device is optimized for distributing reference clocks forIntel®QuickPath Interconnect (Intel QPI), PCIe Gen 1/Gen 2/Gen 3/Gen 4, SAS, SATA, and Intel ScalableMemory Interconnect (Intel SMI)applications. The VCO of the device is optimized to support 100 MHz and133 MHz operation. Each differentialoutput can be enabled through I2Cfor maximum flexibility and power savings.Measuring PCIe clock jitter isquick and easy with the Silicon Labs PCIe Clock Jitter Tool. Download itfor free at
为互联网基础设施提供高性能时钟解决方案的领导厂商Silicon Labs(芯科实验室有限公司)今天宣布推出PCI Express(PCIe)Gen1/2/3扇出缓冲器,此产品为包括服务器、存储器和交换机在内的数据中心应用而设计。针对当今领先的x86主板和服务器系统,新型的Si5310x/11x/019 PCIe缓冲器是业内最高能效的扇出缓冲器,有效扩展了Silicon Labs不断壮大的PCIe计时产品线。凭借灵活的输出数量选项,新型的PCIe缓冲器能够完整满足98% 的基于x86的服务器/存储器主板设计需求。

图1:PCI Express(PCIe)Gen1/2/3扇出缓冲器
多年以来,数据中心设备制造商不得不在有限的供应商中选择通过主要x86CPU和芯片组供应商认证的PCIeGen3缓冲器。这些传统的PCIe缓冲器通常基于十分耗电的恒流输出技术,每个输出至少需要4个片外终端电阻器以及一个参考电阻器,增加了物料清单(BOM)成本。随着能耗和散热成本逐渐成为数据中心设计的关键所在,开发人员越来越倾向于寻求那些既能提供最大能源效率,又符合严格的x86主板规格的计时产品。Silicon Labs的Si5310x/11x/019系列产品能够为设备制造商提供低功耗、标准兼容的PCIe缓冲器产品,这些产品不仅通过了主要x86 CPU和芯片组供应商的认证,而且也获得强大的技术支持。
超过90% 以上的现有主板设计依旧采用基于恒流输出技术的PCIe缓冲器。为了满足这些现有市场的需求,Silicon Labs新型Si53019PCIe恒流缓冲器提供了一个完全认证的直接替换兼容解决方案,并且与传统解决方案相比,能耗减少30%。
为了进一步降低功耗,Silicon Labs的Si5310x和Si5311x器件使用创新的推挽输出架构,可提供业界最低能耗的PCIe缓冲器系列产品。这些器件比恒流缓冲器减少60% 的功耗,同时减少每路输出所需的片外电阻器,显著的减少了片外器件数量,简化了印刷电路板(PCB)的设计。例如,通过使用Silicon Labs的19路输出的Si53119推挽缓冲器代替传统的恒流器件,开发人员能够节省将近1W的能耗,并且减少了39个片外器件。
针对采用新型基于ARM®SoC的超大规模服务器和存储市场的系统设计,Silicon Labs的Si5310x和Si5311x推挽输出芯片也是最佳的PCIe计时解决方案。与基于x86的设计相似,应用于服务器和存储设备的基于ARM的SoC平台,使用PCIe作为主要的系统数据总线和互连方式。随着系统级能效逐渐成为超大规模架构的关键所在,采用推挽输出的新型Si5310x和Si5311x器件便成为了服务器和存储平台设计的理想选择(无论其采用何种CPU架构)。
除了考虑能耗之外,数据中心设备的制造商也面临着保持信号完整性的挑战,因为通常需要在长达60英寸的电路板之间传输时钟信号。在如此长的距离中,PCIe时钟的上升和下降时间将延长并变慢,这也导致抖动性能降低,系统丢包率升高。Silicon Labs的PCIeGen3缓冲器设计旨在能够提供长距离时钟信号传输,同时保持兼容标准的PCIe上升和下降时间规格,从而防止抖动增加和丢包率上升。
Silicon Labs的新型PCIe缓冲器系列产品支持6、8、12、15、19路输出,同时具有恒流和推挽输出缓冲器,这使得开发人员能够为每个应用定制最佳的计时解决方案。Silicon Labs的芯片与传统PCIe缓冲器引脚和功能兼容,凭借增强能源效率、信号完整性和抖动性能,可提供给开发人员最优秀的可选方案。
Silicon Labs时钟产品营销总监James Wilson表示:“移动互联网流量和云计算正在推动更快、更高性能的数据中心设备选择支持PCIe标准和主要x86规范的高精度计时解决方案。我们已经扩展了PCIe计时产品线,现在包括完全符合x86规范的PCIeGen3扇出缓冲器,能够极大降低数据中心设备的功耗、成本和复杂性。我们新型的PCIe产品有效补充了Silicon Labs的任意频率时钟发生器,为服务器、交换机和存储设计提供了单芯片时钟树解决方案。”
Silicon Labs提供广泛的时钟产品线,包括频率灵活的时钟发生器、抖动衰减器、时钟缓冲器、PCIe时钟和振荡器,能够满足各类物联网基础设施应用。这些高性能的计时解决方案使得开发人员能够通过单一的一站式购齐的供应商,为数据中心、核心网络、无线基础设备、宽带接入以及测试和测量设计提供满足需求的完整计时解决方案。
供货
Si531xx和Si53019PCIe扇出缓冲器现在已经量产,可提供样片。为了加速采用推挽输出时钟缓冲器的服务器和存储应用的开发,Silicon Labs提供了Si53108-EK、Si53112-EK和Si53119-EK评估板。
缓冲器在不同的领域有不同的含义。
在计算机领域,缓冲器指的是缓冲寄存器,它分输入缓冲器和输出缓冲器两种。前者的作用是将外设送来的数据暂时存放,以便处理器将它取走;后者的作用是用来暂时存放处理器送往外设的数据。有了数控缓冲器,就可以使高速工作的CPU与慢速工作的外设起协调和缓冲作用,实现数据传送的同步。由于缓冲器接在数据总线上,故必须具有三态输出功能。

在其他领域,还有电梯缓冲器,汽车弹簧缓冲器等,其目的是用于减缓速度,提高安全性和舒适性。
接口集成电路专用语
最基本线路构成的门电路存在着抗干扰性能差和不对称等缺点。为了克服这些缺点,可以在输出或输入端附加反相器作为缓冲级;也可以输出或输入端同时都加反相器作为缓冲级。这样组成的门电路称为带缓冲器的门电路。
带缓冲输出的门电路输出端都是1个反相器,输出驱动能力仅由该输出级的管子特性决定,与各输入端所处逻辑状态无关。而不带缓冲器的门电路其输出驱动能力与输入状态有关。另一方面。带缓冲器的门电路的转移特性至少是由3级转移特性相乘的结果,因此转换区域窄,形状接近理想矩形,并且不随输入使用端数的情况而变化、加缓冲器的门电路,抗干扰性能提高10%电源电压。此外,带缓冲器的门电路还有输出波形对称、交流电压增益大、带宽窄、输入电容比较小等优点。不过,由于附加了缓冲级,也带来了一些缺点。例如传输延迟时间加大,因此,带缓冲器的门电路适宜用在高速电路系统中。
基本原理
在CPU的设计中,一般输出线的直流负载能力可以驱动一个TTL负载,而在连接中,CPU的一根地址线或数据线,可能连接多个存储器芯片,但存储器芯片都为MOS电路,主要是电容负载,直流负载远小于TTL负载。故小型系统中,CPU可与存储器直接相连,在大型系统中就需要加缓冲器。
任何程序或数据要为CPU所使用,必须先放到主存储器(内存)中,即CPU只与主存交换数据,所以主存的速度在很大程度上决定了系统的运行速度。程序在运行期间,在一个较短的时间间隔内,由程序产生的地址往往集中在存储器的一个很小范围的地址空间内。指令地址本来就是连续分布的,再加上循环程序段和子程序段要多次重复执行,因此对这些地址中的内容的访问就自然的具有时间集中分布的倾向。数据分布的集中倾向不如程序这么明显,但对数组的存储和访问以及工作单元的选择可以使存储器地址相对地集中。这种对局部范围的存储器地址频繁访问,而对此范围外的地址访问甚少的现象被称为程序访问的局部化(Locality of Reference)性质。由此性质可知,在这个局部范围内被访问的信息集合随时间的变化是很缓慢的,如果把在一段时间内一定地址范围被频繁访问的信息集合成批地从主存中读到一个能高速存取的小容量存储器中存放起来,供程序在这段时间内随时采用而减少或不再去访问速度较慢的主存,就可以加快程序的运行速度。这个介于CPU和主存之间的高速小容量存储器就称之为高速缓冲存储器,简称Cache。不难看出,程序访问的局部化性质是Cache得以实现的原理基础。同理,构造磁盘高速缓冲存储器(简称磁盘Cache),也将提高系统的整体运行速度CPU一般设有一级缓存(L1 Cache)和二级缓存(L2 Cache)。一级缓存是由CPU制造商直接做在CPU内部的,其速度极快,但容量较小,一般只有十几K。PⅡ以前的PC一般都是将二级缓存做在主板上,并且可以人为升级,其容量从256KB到1MB不等,而PⅡ CPU则采用了全新的封装方式,把CPU内核与二级缓存一起封装在一只金属盒内,并且不可以升级。二级缓存一般比一级缓存大一个数量级以上,另外,在CPU中,已经出现了带有三级缓存的情况。
高速缓冲存储器
高速缓冲存储器,即Cache。我们知道,数据分布的集中倾向不如程序这么明显,如果把在一段时间内一定地址范围被频繁访问的信息集合成批地从主的系统中,CPU访问数据时,在Cache中能直接找到的概率,它是Cache的一个重要指标,与Cache的大小、替换算法、程序特性等因素有关。增加Cache后,CPU访问主存的速度是可以预算的,64KB的Cache可以缓冲4MB的主存,且命中率都在90%以上。以主频为100MHz的CPU(时钟周期约为10ns)、20ns的Cache、70ns的RAM、命中率为90%计算,CPU访问主存的周期为:有Cache时,20×0.9+70×0.1=34ns;无Cache时,70×1=70ns。由此可见,加了Cache后,CPU访问主存的速度大大提高了,但有一点需注意,加Cache只是加快了CPU访问主存的速度,而CPU访问主存只是计算机整个操作的一部分,所以增加Cache对系统整体速度只能提高10~20%左右。
责任编辑:Davia
【免责声明】
1、本文内容、数据、图表等来源于网络引用或其他公开资料,版权归属原作者、原发表出处。若版权所有方对本文的引用持有异议,请联系拍明芯城(marketing@iczoom.com),本方将及时处理。
2、本文的引用仅供读者交流学习使用,不涉及商业目的。
3、本文内容仅代表作者观点,拍明芯城不对内容的准确性、可靠性或完整性提供明示或暗示的保证。读者阅读本文后做出的决定或行为,是基于自主意愿和独立判断做出的,请读者明确相关结果。
4、如需转载本方拥有版权的文章,请联系拍明芯城(marketing@iczoom.com)注明“转载原因”。未经允许私自转载拍明芯城将保留追究其法律责任的权利。
拍明芯城拥有对此声明的最终解释权。
相关资讯
:
基于MC33771主控芯片的新能源锂电池管理系统解决方案

AMIC110 32位Sitara ARM MCU开发方案

基于AMIC110多协议可编程工业通信处理器的32位Sitara ARM MCU开发方案
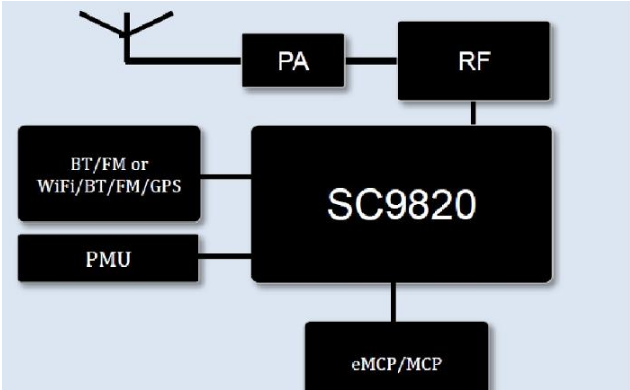
基于展讯SC9820超低成本LTE芯片平台的儿童智能手表解决方案

基于TI公司的AM437x双照相机参考设计
基于MTK6580芯片的W2智能手表解决方案









 2012- 2022 拍明芯城ICZOOM.com 版权所有 客服热线:400-693-8369 (9:00-18:00)
2012- 2022 拍明芯城ICZOOM.com 版权所有 客服热线:400-693-8369 (9:00-18:00)


