



 产品分类
产品分类
AI黄金时代:看中国巨头如何多足鼎立?
 397
397
 拍明
拍明
从2017年开始,中国一大批AI公司融资信息频频曝光,从2千万到数亿美元,而2017年也被业界称之为“中国AI元年”。
AI的黄金年代真的来了吗?
诚然,资本的大规模介入到AI领域,必定会带动这一行业的发展,在这一过程中我们会看到业务雷同的技术,而其中也一定会有胜出者,也一定会有失败者。
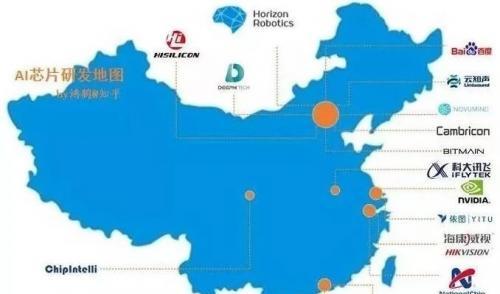
在这里,我们盘点一下目前已经走上前台的AI企业,这里面一定会有企业很快登陆中国的股市,此前传言证监会会为“独角兽”开掘绿色通道,绝不会是空穴来风。

北京中科寒武纪科技有限公司
这家公司有中科院背景,面向深度学习等人工智能关键技术进行专用芯片的研发,可用于云服务器和智能终端上的图像识别、语音识别、人脸识别等应用。
寒武纪深度学习处理器采用的指令集DianNaoYu由中国科学院计算技术研究所陈云霁、陈天石课题组提出。模拟实验表明,采用DianNaoYu指令集的寒武纪深度学习处理器相对于x86指令集的CPU有两个数量级的性能提升。
目前,寒武纪系列已包含三种原型处理器结构:寒武纪1号(英文名DianNao,面向神经网络的原型处理器结构);寒武纪2号(英文名DaDianNao,面向大规模神经网络);寒武纪3号(英文名PuDianNao,面向多种机器学习算法)。
2016年推出的寒武纪1A处理器(Cambricon-1A)是世界首款商用深度学习专用处理器,面向智能手机、安防监控、可穿戴设备、无人机和智能驾驶等各类终端设备

北京中星微电子有限公司
中星微在2016年6月20日率先推出中国首款嵌入式神经网络处理器(NPU)芯片,这是全球首颗具备深度学习人工智能的嵌入式视频采集压缩编码系统级芯片,取名“星光智能一号”。
目前“星光智能一号”出货量主要集中在安防摄像领域,其中包含授权给其他安防摄像厂商部分。未来将主要向车载摄像头、无人机航拍、机器人和工业摄像机方面进行推广和应用。
这款基于深度学习的芯片运用在人脸识别上,最高能达到98%的准确率,超过人眼的识别率。该NPU采用了“数据驱动”并行计算的架构,单颗NPU(28nm)能耗仅为400mW,极大地提升了计算能力与功耗的比例。
研发“星光智能一号”耗时三年时间。中星微集团聚集了北京、广东、天津、山西、江苏、青岛、硅谷的研发力量,采用了先进的过亿门级集成电路设计技术及超亚微米芯片制造工艺,在TSMC成功实现投片量产。

北京地平线机器人技术研发有限公司
地平线机器人由前百度深度学习研究院负责人余凯创办,致力于打造基于深度神经网络的人工智能“大脑”平台-包括软件和芯片,可以做到低功耗、本地化的解决环境感知、人机交互、决策控制等问题。
其中,软件方面,地平线做了一套基于神经网络的OS,已经研发出分别面向自动驾驶的的“雨果”平台和智能家居的“安徒生”平台,并开始逐步落地。硬件方面,未来地平线机器人还会为这个平台设计一个芯片——NPU(Neural Processing Unit),支撑自家的OS,到那时效能会提升2-3个数量级(100-1000倍)。
地平线的最终产品不止芯片,而是一个核心控制模块,具有感知、识别、理解、控制的功能。把这个控制模块做成产品去跟合作方做集成。
换句话说,地平线提供的是一个带有人工智能算法的解决方案。
2017年12月,地平线发布了面向智能驾驶的征程(Journey)1.0处理器和面向智能摄像头的旭日(Sunrise)1.0处理器。这是完全由地平线自主研发的人工智能芯片,采用地平线的第一代BPU架构,具有全球领先的性能:可实时处理1080p@30视频,每帧中可同时对200个目标进行检测、跟踪、识别,典型功耗1.5W,每帧延时小于30ms。

北京深鉴科技有限公司
深鉴科技由清华团队创办,其产品称作“深度学习处理单元”(Deep Processing Unit,DPU),目标是以ASIC级别的功耗,来达到优于GPU的性能,目前第一批产品基于FPGA平台。
从官方提供的数据来看,嵌入式端的产品在性能超过Nvidia TK1 的同时,功耗、售价仅为后者的1/4左右。服务器端的产品,性能接近Nvidia K40 GPU ,但功耗只有35瓦左右,售价300美元以下,不足后者的1/10。
深鉴科技的创始人汪玉博士是清华大学电子工程系副教授,是清华大学的首批终身教职,是ACM FPGA技术委员会亚太地区唯一成员。
深鉴科技着力于打造基于DPU的端到端的深度学习硬件解决方案,除了承载在硬件模块(订制的PCB板)上的DPU的芯片架构外,还打造了针对该架构的DPU压缩编译工具链SDK。
产品的应用领域分为终端和云端两类。其中嵌入式端的产品将主要应用在无人机、安防监控、机器人、AR等领域,目前已经与一家知名无人机厂商建立了合作。
服务器端的产品将主要面向大型互联网公司的语音处理、图像处理等。目前也已经与国内知名互联网公司展开合作,在兼容对方现有机房的情况下,功耗降低80%,语音识别的准确率提升了5%-7%。
杭州国芯科技股份有限公司
杭州国芯是一家本土的芯片公司,成立于2001年,已经有17年的历史。最初杭州国芯主要做数字电视芯片、机顶盒芯片,产品已遍销全球。

在2016年初,杭州国芯就成立了AI事业部,2017年10月31日,杭州国芯发布了一款面向物联网市场专用AI芯片GX8010,能够在本地离线、低功耗、可移动的工作。GX8010 芯片中内置了杭州国芯自主研发的 gxNPU 神经网络处理器。GX8010 作为一款语音 AI 芯片,主要面向智能音箱、智能电视、智能玩具 / 幼教领域。

上海西井信息科技有限公司
西井科技成立于2015年5月,是一间专注研究Neuromorphic Engineering神经形态工程的类脑强人工智能商业公司。westwelllab致力构造一种完全跳脱于冯诺依曼结构的神经形态的芯片结构——即模拟人脑神经元工作原理而制造出的芯片,它既具备人脑的学习能力,又具备强大的特定运算能力,仅需一块邮票大小的芯片,就能模仿人类大脑在短时间内处理海量的感官信息。
这家致力于开发“类脑人工智能芯片+算法”的科技公司,其芯片用电路模拟神经,成品有100亿规模的仿真神经元。西井用FPGA模拟神经元以实现SNN的工作方式,其产品命名为Deepsouth,正是和IBM的truenorth成竞品。由于架构特殊,这些芯片计算能力强,可用于基因测序、模拟大脑放电等医疗领域。
西井科技还有一款5000万个神经元的商用芯片。除了自我学习外,它的传统计算能力也极强,能将基因测序从两周缩短到数个小时。由于体积小、功耗是同类芯片几十分之一,其它便携式医疗设备也可使用这款芯片。

成都启英泰伦科技有限公司
成都启英泰伦科技有限公司成立于2015年11月,是一家专注于人工智能芯片设计及配套智能算法引擎开发的公司。
2016年9月,公司推出了全球首款深度神经网络智能语音识别芯片CI1006。CI1006芯片集成我公司自主知识产权的脑神经网络处理单元BNPU,也采用了ARM最为先进的MCU 内核Cortex-M4F,形成专用的SoC架构,具备高性能、低功耗、高识别率、低成本等优点,在应用方面,该芯片可以支持本地语音检测、唤醒,以及数百条离线命令词条的识别,可应用于智慧家居、智慧照明、智慧汽车、智慧玩具、机器人等领域。

深圳云天励飞技术有限公司
深圳云天励飞技术有限公司是一家专注于视觉人工智能领域的公司,致力于打造基于视觉芯片、深度学习和大数据技术的“视觉智能加速平台”,为平安城市、智慧商业、工业智造、无人系统、机器人等行业的千家企业提供视觉智能应用解决方案和开发平台,最终实现公司愿景“让智能无处不在”。
公司已经组建了一支四十多人的芯片团队自主研发安防厂商急缺的AI芯片,并将于明年生产投片。通过该芯片实现视觉识别和大数据分析,即公众通常理解的“天眼系统”。
Think Force成立于2017年,由来自芯片设计、算法软件、系统开发领域的资深专家创立。公司主要设计融合一流AI算法和先进制成工艺的智能芯片,并以此构建人工智能硬件平台,提供一站式行业应用解决方案。

Think Force聚集了一批国际一流的核心芯片技术人员,在IBM、Cadence、AMD等国际知名的大型芯片软件企业有平均超过10年的工作经验。团队成员充分掌握28nm、16nm、14nm等先进制程技术,拥有服务器CPU、高带宽显存GPU、SSD等超过20款、累计过亿出货量的成功芯片案例。
据介绍,ThinkForce计划推出的AI芯片基于业界先进的半导体制程工艺,采用自主研发的微内核ManyCore架构,能完成AI云虚拟化调度在芯片级的实现,此架构将AI云的弹性计算和调度提升一个量级,类似CPU的虚拟化给云计算的弹性调度带来成倍的成本节约。同时,该技术结合自主研发的固件和TFDL软件SDK能够实现对于各类神经网络模型的计算加速,相对于Nvidia主流计算卡能实现5倍以上的功耗和成本节省。

责任编辑:Davia
【免责声明】
1、本文内容、数据、图表等来源于网络引用或其他公开资料,版权归属原作者、原发表出处。若版权所有方对本文的引用持有异议,请联系拍明芯城(marketing@iczoom.com),本方将及时处理。
2、本文的引用仅供读者交流学习使用,不涉及商业目的。
3、本文内容仅代表作者观点,拍明芯城不对内容的准确性、可靠性或完整性提供明示或暗示的保证。读者阅读本文后做出的决定或行为,是基于自主意愿和独立判断做出的,请读者明确相关结果。
4、如需转载本方拥有版权的文章,请联系拍明芯城(marketing@iczoom.com)注明“转载原因”。未经允许私自转载拍明芯城将保留追究其法律责任的权利。
拍明芯城拥有对此声明的最终解释权。
相关资讯
:
BAT剑指科大讯飞,能否让其重蹈Nuance覆辙?

三星在中国一面撤资,一面增资是为何?
半导体激光治疗仪是骗局吗?

2016全球十大电子元器件分销商排行榜

2016年10大全球电子元器件代理商排行一览表

STM32学习笔记:通用定时器基本定时功能









 2012- 2022 拍明芯城ICZOOM.com 版权所有 客服热线:400-693-8369 (9:00-18:00)
2012- 2022 拍明芯城ICZOOM.com 版权所有 客服热线:400-693-8369 (9:00-18:00)


