



 产品分类
产品分类
基于RISC微处理器+FPGA芯片4vfx12ff668-10的模块流水线的设计方案
 44
44
 拍明
拍明
原标题:基于RISC微处理器的模块流水线的设计方案
1、引言
随着微电子技术的不断发展,超大规模集成电路的集成度和工艺水平不断提高,将整个应用电子系统集成在一个芯片中(SoC),已成为现代电子系统设计的趋势。作为SoC的核心控制部分——微处理器,极大地影响了整个系统的设计。
本文所设计实现的微处理器符合Michael Slater对RISC的定义,采用流水线并行技术提高其执行效率。本文主要讨论了RISC微处理器各关键模块的设计与实现,通过对模块的分析设计合理的流水线,并着重讨论了流水线相关性问题,及其解决办法,最后给出综合和仿真结果。
2 、体系结构
2.1 指令集
微处理器指令长度固定为32位,指令格式如图1,三种指令格式分别为寄存器(R)类型、立即(I)类型和跳转(J)类型,结构固定简单,便于设计和译码。微处理器主要实现了数据处理常用的指令,包括有算术运算(add,sub,addi,subi)、逻辑运算(and,andi,or,ori,nor,xor,xori)、比较运算(slt,sltu,slti,slTIu)、移位(rotr,rotl,srl,sll,sra,)、load/stroe指令(lw,sw)、分支跳转指令(bne,beq,bgez,bgtz,blez,bltz,jump)和其它指令(nop,rst,clr) 共32条指令。
2.2 系统结构
微处理器系统结构如图2所示,主要由ALU、译码单元、指令存储器、数据存储器、寄存器堆和写回逻辑等构成。系统特点如下:采用Harvard结构;32个32位的寄存器,16KB的片内指令存储器,16KB片内数据存储器;32位地址,寻址方式简单,只有立即数寻址、寄存器寻址和寄存器间接寻址三种。

图1、指令格式

图2、微处理器系统结构图
3、关键部件
ALU是处理器的核心部件,主要完成算术、逻辑、比较和移位等运算。该ALU数据宽度为32位,操作码宽度为5位。ALU根据译码单元提供的操作码,进行各种算术逻辑运算。
寄存器堆regbank,RISC处理器的大部分指令通过寄存器来进行,所以寄存器的设计关系到整个体系结构,根据对体系结构的分析,需要设计32个通用寄存器。在FPGA设计中我们可以使用Xilinx的IP核生成器生成双口RAM[3],宽度为32,深度为32,一端只读,另一端支持读写。
译码单元控制着处理器各个部件的运行,通过对指令进行译码产生信号,控制各模块的操作,包括指令取指操作,寄存器堆存取操作,ALU操作,操作数选择,数据存储器访问和数据写回等。
指令存储器、数据存储器,是分别用以存放程序指令和数据的存储单元。在本设计中指令存储器以单口RAM IP核生成,并赋予初值,数据宽度为32位,深度为4096,即16KB大小。数据存储器也以单口RAM IP核生成,支持读写,写模式为只写,数据宽度为32位,深度为4096,即16KB大小。
取指逻辑包括程序计数器PC和地址加法器,主要完成从指令存储器读取指令和计算下一条指令的地址。
除了以上关键部件外,处理器还包括其它部件,如操作数选择单元,写回逻辑单元等。
4、 流水线设计
4.1 流水线
流水线是提高CPU处理速度的关键技术,为了提高指令执行速度,将整个执行过程划分为几个单元,各个单元完成固定部分工作,就像工厂的流水线作业一样。在流水线划分之前先对各处理关键模块通过综合工具进行大概的时延分析,在这使用ISE内嵌的综合工具XST,虽然XST在算术、功能等方面不如业界流行的综合工具Synplify Pro,但凭着对自己的器件熟悉,XST对Xilinx 芯片的支持是最直接。关键部件综合测试内部逻辑延时情况如下表1,从表中可以看到,最大延时部件是ALU(10.19ns),由于采用流水线,ALU源操作数据有多个选择,所以如果以ALU和数据选择器作为一个流水段,其他流水段的组合时延不超过这一阶段即可。经过分析,该流水线分为五段,即取指、译指、执行、访问存储器和写回五个阶段。预测系统时钟期为13.5ns。

4.2 流水线相关性问题及其解决
由于流水线的并行处理,产生指令相关性问题,一般存在三种相关:结构相关、数据相关和控制相关。在这主要讨论数据相关和控制相关二种。
数据相关,是指当一条指令的执行依赖于前面某一条未执行完指令执行结果时,这两条指令将发生数据相关。数据相关的解决通常有两种方法,一是推后分析法,即遇到数据相关时,推后本条指令的分析,直到相关的数据写入寄存器堆中;另一种是旁路技术(Forwarding)[4],即不必等到所需的数据写入到相关的寄存器中,而是经过专门设置的数据通路读取所需要的数据。这两种方法各有春秋,推后分析法容易设计,但因等待相关数据写入寄存器堆而引起了流水线断流;旁路技术(Forwarding),利用专用数据路径消除了一部分流水线断流,提高了处理器的速度,但要占用一定的逻辑资源。如果你的可编程逻辑芯片资源足够,采用旁路技术不失为一个提高处理器速度的好办法。本设计就是通过设置专用数据通路解数据相关,将前面相关指令还未写入寄存器堆的执行结果,提前提供给运算器使用,以减少流水线断流,但相关指令是load指令,并数据还没读出时,只能通过延迟一个周期以保证操作数的正确性。
控制相关,是指当执行到分支跳转指令时,因无条件分支目标地址还未计算出来,条件分支还未知条件是否成立等原因,而与后面的指令发生相关。控制相关问题的解决一般通过两方面来解决,一方面通过尽早判断分支条件是否成立和尽早计算出分支转移的PC值来解决,在本设计中,分支跳转条件的判断和分支跳转目标地址的计算,提前到译码阶段由专门的比较器和加法单元来完成,这样比在执行阶段进行条件判断和地址计算流水线可以减少断流;另一方面通过转移预测技术的硬件“猜测法”来解决,是指在当前还无法确定分支跳转指令的执行情况,无法确定下一条指令时,依据指令过去的行为来预测将来的行为。在本设计中通过选址单元猜测分支条件不成立,继续执行本指令的下一地址指令。猜测是否成功由译码单元决定,如果预测成功继续执行,否则重新取指并预取的指令无效。
4.3 流水线时序设计
根据对各关键部件和流水线相关性的分析,设计系统流水线时序如图3所示。流水线的各个阶段在时钟上升时开始执行。取指阶段在时钟上升沿时读取程序计数器的指令地址,在本周期的时钟下降沿时从指令存储器读取指令。由于在同一周期内要对寄存器堆进行写操作和读操作,为了避免因数据带来的冲突,寄存器堆在前半周期进行写操作,后半周期进行读操作。

图3、系统时序图
4.4 流水线各阶段设计与实现
取指阶段,主要完成两个任务,一是根据程序计数器PC里的指令地址从指令存储器I_mem里读取指。另一个任务主要完成PC+1计算和下一条指令地址的猜测。对下一条指令的猜测主要是假设分支条件不成立,猜测下一条指令地址是本指令地址的下一地址,除了对下一条指令的猜测,还完成对上一次的猜测的确认。本指令地址的确认主要是完成如果上一条指令是分支指令时,如果分支条件不成立,本指令地址猜测是正确,指令有效,继续执行,否则本指令无效,重新再取指。
译码阶段,是整个系统中的关键控制阶段,不但进行指令译码,从寄存器堆中读取操作数,而且判断分支指令的跳转条件,计算跳转地址和处理数据相关性问题。这一阶段主要器件有译码单元,寄存器堆,加法器,比较器和地址选择器等。译码单元,可以说是核心控制单元,根据指令代码译码成各种控制信号控制各个单元的控制,而且进行数据相关处理。
译码单元,因采用旁路技术来解决数据相关性问题,因此在译码单元中参照前两条指令的目的寄存器号来确定是否发生数据相关性,如果发生数据相关,产生delay信号,使下一条指令重新取指。译码单元主要控制信号如下:
op_alu[4:0]:ALU操作控制信号,控制ALU执行相应的算术逻辑运算。
delay:延迟控制信号,尽管采用了设置专用路径,避免了大部分的因数据相关带来的延迟,但是当指令的源操作数是前一条指令是load读存储器指令或乘法指令的结果时,需要延迟一个周期,以解决写后读的数据相关性问题。
bj[1:0]:分支跳转信号,控制地址选择器选择跳转地址。
alua[1:0],alub[1:0]:ALU操作数选择控制信号,ALU源操作数一般来自寄存器或立即数,但当采用设置专用路径技术后,还有可能来自于与该指令相关的前两条指令当前的运行结果。最后一些使能控制信号,如寄存器写使能、数据存储器读写使能等。
执行阶段主要完成指令的逻辑运算工作,ALU根据操作控制码对所提供的操作数进行相应的操作。读/写储存阶段主要完成存储器中数据的读取和写入,是微处理器系统中比较复杂的功能,在这主要完成微处理器内部数据存储器的读写。写回阶段是流水线的最后一个阶段,它将运行结果写回目的寄存器中。
5、 综合与仿真结果
本设计采用ISE的开发环境,各个功能模块均分别在XST和ISE Simulator进行了逻辑综合和功能仿真。选择目标器件为4vfx12ff668-10,顶层模块综合结果如表2。
从综合结果可以看出,该处理器占FPGA芯片可编程逻辑单元不超过10%,最大工作频率达到74.59MHz,达到了设计要求。

使用ISE自带的仿真工器进行功能仿真,测试程序如下:
1: 20010001; //addi $1,$0,1; 6:14430003; //bne $2,$3,3;
2: 00201024; //and $2,$1,$0; 7: 24240000; //subi $4,$1,0;
3: 8C020002; //lw $2,2; 8: 00231024; //and $2,$1,$3;
4: 00221827; //rotr $1,$3,2; 9: 00412822; //sub $5,$2,$1;
5: 00030881; //xor $3,$1,$2; 10:08000005; //jump 5;
通过对波形的分析,如图4,该处理器达到了设计目的,各条指令能够正确执行,当发生数据相关时,ALU通过专用路线能够获得正确的操作数,或者发生延时。当遇到分支跳转指令时,取指逻辑能够猜测下一条指令地址,并指令译码后判断猜测是否正确。

图4、仿真测试波形
6 、结论
流水线处理器的设计关键是流水线各阶段的设计和因流水线引起的各种相关性问题的解决。本文通过对RISC处理器各关键部件进行分析,合理安排流水线。在流水线设计中,通过对因流水线引起的相关性问题进行分析研究,采用旁路技术来解决数据相关性的写后读问题,采用硬件猜测法预取分支跳转指令的目标指令,以减少流水线断流提高处理器处理速度,从综合和仿真的结果可以看到设计达到了预期的目标。本设计使用Verilog进行硬件描述设计,具有较好的可读性和可移植性,可以根据需要进行功能的增减,与其他IP核集合成SoC系统。
本文作者创新点:通过对RISC处理器的分析,设计处理器关键模块,并进行时延分析,合理地设计流水线。在流水线相关性问题方面,采用旁路技术来解决数据相关性的写后读问题,采用硬件猜测法预取分支跳转指令的目标指令,以减少流水线断流提高处理器处理速度。
责任编辑:David
【免责声明】
1、本文内容、数据、图表等来源于网络引用或其他公开资料,版权归属原作者、原发表出处。若版权所有方对本文的引用持有异议,请联系拍明芯城(marketing@iczoom.com),本方将及时处理。
2、本文的引用仅供读者交流学习使用,不涉及商业目的。
3、本文内容仅代表作者观点,拍明芯城不对内容的准确性、可靠性或完整性提供明示或暗示的保证。读者阅读本文后做出的决定或行为,是基于自主意愿和独立判断做出的,请读者明确相关结果。
4、如需转载本方拥有版权的文章,请联系拍明芯城(marketing@iczoom.com)注明“转载原因”。未经允许私自转载拍明芯城将保留追究其法律责任的权利。
拍明芯城拥有对此声明的最终解释权。
相关资讯
:
基于MC33771主控芯片的新能源锂电池管理系统解决方案

AMIC110 32位Sitara ARM MCU开发方案

基于AMIC110多协议可编程工业通信处理器的32位Sitara ARM MCU开发方案
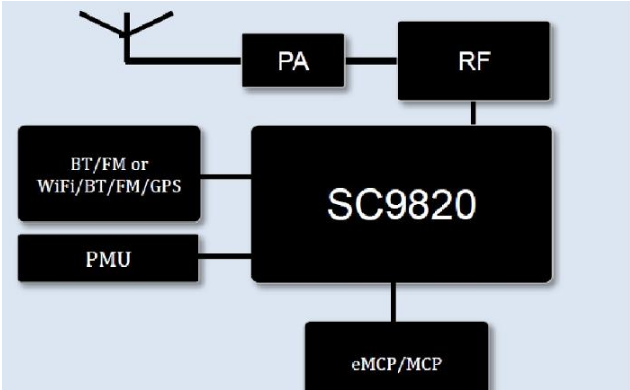
基于展讯SC9820超低成本LTE芯片平台的儿童智能手表解决方案

基于TI公司的AM437x双照相机参考设计
基于MTK6580芯片的W2智能手表解决方案









 2012- 2022 拍明芯城ICZOOM.com 版权所有 客服热线:400-693-8369 (9:00-18:00)
2012- 2022 拍明芯城ICZOOM.com 版权所有 客服热线:400-693-8369 (9:00-18:00)


