



 产品分类
产品分类
片上多核处理器共享资源分配与调度策略研究综述(二)
 10
10
 拍明
拍明
原标题:片上多核处理器共享资源分配与调度策略研究综述(二)
1 基于缓存分区的分配调度策略概述
1.1 缓存分区的背景
在CMP 系统中,缓存通常是私有的,而缓存(last level cache,LLC)则在各个核间共享(下文提到的缓存如无特别说明都是指LLC)。
共享缓存使得多个线程可以共享某些数据,降低通讯延迟,同时减少数据的冗余备份,提高缓存空间利用率。但是,线程间对于有限共享缓存空间的争夺,也会导致缓存失效率的上升,影响系统的吞吐量和公平性。
在单核单线程处理器中为常用的缓存替换算法是LRU.LRU 不区分访存请求的线程,同等对待所有访存请求,每次发生缓存失效时替换近少访问的缓存块。LRU 在单线程环境中能够有效地提高缓存利用率。然而,在多线程环境下,由于线程间对于共享缓存空间的争夺,仍然采用LRU 算法的话,一个频繁发生缓存失效的线程(例如,流媒体应用)会不公平地替换掉其他线程的有用数据块,占用大量乃至全部缓存空间,从而导致其他线程的缓存失效率(MissRate)①大幅上升,破坏系统的公平性;另外,一个产生大量缓存失效的线程,其数据的复用率(reused)可能很低,而其他线程被替换掉的却可能是一些常用数据,从而降低了共享缓存的利用率,导致总的缓存失效率上升。无论哪种情况,终结果都会使得系统的性能受到严重影响。
1.2 缓存分区的基本思想
为了降低线程间争夺缓存空间带来的影响,一种直观的想法是对缓存进行分区,通过明确地把缓存空间分配给各个核来避免线程间的干扰。一旦某部分缓存被划分给某个线程,由该线程独享这部分缓存空间,其他线程无权替换这部分缓存空间中的数据,避免了由于缓存争夺所带来的额外缓存失效,使得所有线程的请求都能够得到合理服务。缓存分区之后,对单个线程而言,相当于运行在单线程环境中一样,因此,在各缓存分区内可以仍然采用LRU算法。
简单也容易实现的的缓存分区方式是在程序运行前将缓存平均划分给CMP 系统中的各个核,称之为静态分区。但这种做法的缺点是明显的,不同线程对于缓存空间需求不一样,并且即使同一个线程在不同的执行阶段对缓存空间的需求也可能不一样,而静态分区策略不能有效反映这种情况。部分线程可能划分到超出需求的缓存空间,导致缓存空间的浪费,而另一部分线程对于缓存空间的需求却没有得到满足。静态缓存分区策略实际上是把二级缓存当做了各个处理器的私有缓存的扩充,失去了多核共享缓存所能带来的好处。近年来的大量研究中都不再采用静态分区策略。
1.3 动态缓存分区
显然,只有知道各线程的具体访存行为特征和缓存需求,才能作出的缓存分区决策。制定一个公平有效的缓存分区策略,需要一个明确的性能优化目标,并且根据线程所处的具体执行环境与执行阶段,充分利用线程访存行为的动态特征。在共享缓存分区中用到的程序动态特征一般指线程在划定不同大小的缓存空间下所对应产生的缓存失效率。
动态缓存分区策略的优化目标一般包括两类,吞吐量和公平性。吞吐量是针对系统的整体性能而言。对于动态缓存分区策略,一个常用的评估吞吐量的指标是共享缓存产生的总缓存失效率,通过化缓存失效率达到化系统吞吐量的目标;同时,缓存失效率低,意味着处理器核等待数据返回的阻塞等待时间减少,提交指令的速度更快,因此,另一个与系统吞吐量相关的指标是IPC(instructiONsper cycle)。公平性则是指系统中并行运行的多个线程能够公平的使用共享缓存,不会存在某些线程占有大部分缓存空间,导致其他线程的缓存失效率大幅增长,性能受到重大影响;公平性同时关注系统中的每个线程,尽量保证所有线程的服务质量得到同等程度的改善。
基于不同的性能优化目标,提出的缓存分区策略通常有很大分别。Hsu 等人在其相关研究中即根据优化目标的不同,命名了3 类调度策略:第1类缓存调度策略可称为“capitalist”,该类策略对于各线程的访存请求无限制,任其自由争夺共享资源,“适者生存”,为常见的即为通用的LRU 替换策略,但是这类调度策略在多线程环境下通常对于系统的吞吐量和公平性都有影响;第2 类是以化系统吞吐量为优化目标的“utilitarian”,该类策略忽视公平性,无法保证单个线程的性能表现;一类是以系统公平性为目标的“communist”,该类策略尽量确保并行执行的各线程的服务质量得到同等程度的改善,不会有某些线程的性能受到严重影响。
在现代商业通用处理器上通常有用于计算系统总缓存失效率的部件,但是制定动态缓存分区策略需要更详细地知道各个线程的访存特征信息。一些特别用于获取线程访存行为特征的辅助硬件是必要的,本文将在1.3.1 节中给出相关介绍。
在取得必需的访存信息后,即可以根据不同的优化目标制定相应的缓存分区策略,在1.3.2 节和1.3.3 节中将分别从追求化吞吐量和公平性的角度对缓存分区进行研究。在1.3.4 节则针对缓存分区粒度过大(通常是按路分区)的问题介绍了一些解决方案。
1.3.1 访存监控器
大多数商业通用处理器都有一个硬件缓存监控器。缓存监控器包括两类计数器,一类用于计数系统总的访存数,另一类计数系统总的缓存失效数,由此可以计算出系统的缓存失效率。但如前所述,要制定动态缓存分区策略,还需要一些特别的辅助硬件来获取各个线程访存行为的特征信息。对于缓存分区而言,线程在各种可能的缓存空间下对应产生的缓存失效率是一个极其有用的信息。一种简单的做法是把每个线程在各种缓存配置下分别执行以获取相应缓存失效率。显然,这种方法过于低效,没有实用性。
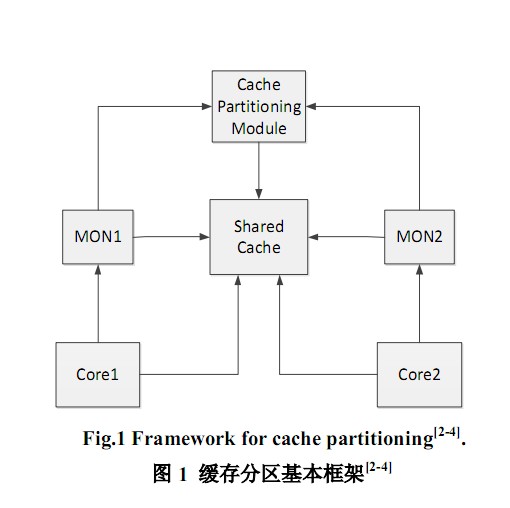
当多个线程并行运行时,为了在不实际改变缓存配置的前提下,获取各线程在不同缓存空间对应的缓存失效率,Hsu 等人在文献[2-3]中提出一种访存监控器(memory monitor,MON)。对于N 路组相联缓存,每个MON 有N 个路计数器(way-counter)。
这组路计数器根据线程对缓存各路的使用情况按照LRU 次序排列。当对一个MRU(most recently used)缓存路中的缓存行发生缓存命中时,counter(0)增加1;当对一个LRU 缓存路中的缓存行发生缓存命中时,counter(N-1)增加1,以此类推。MON 另有一个计数器用于计数一个线程对共享缓存的总访存次数。
为每个处理器核配置一个MON 用于记录运行在该核上的线程的访存信息。从而,当该线程只能使用N 路缓存的其中几路时,只需将另几路缓存的路计数器中的缓存命中数相加,就可以得出由于减少的可用缓存空间所带来的额外缓存失效数。
通过MON 获取线程访存信息并制定相应缓存分区策略的基本框架如图1 所示。图1 中,该CMP系统包括两个处理器核,共享缓存和一个缓存分区模块;每个核有一个MON,用于获取运行在该核上线程的访存信息;然后将各个线程的访存信息集中到缓存分区模块(cache partitioning module),根据具体的优化目标,制定适当的缓存分区决策。
每路缓存对应一个计数器的结果是将一路缓存作为一个缓存分区单元,在系统的缓存路数足够多且线程数较少时,这种做法可以取得较为理想的效果。但是当线程数增多时,缓存的路数很难跟着成规模地增长,这种按路分区的做法会显得粒度过大。
为了获取更为的细粒度信息,也可以再为每一个缓存组增加一个组计数器(set-counter),这样又会带来过大的硬件开销。一种折中的做法是,将M 组缓存看作一个集(group),增加相应的集计数器(group-counter),从而做到兼顾性能与开销。
通过MON 既可以得到线程随着可用缓存空间减小导致的缓存失效率的增加,也能反过来计算当线程的可用缓存空间增加时,该线程缓存失效率的降低。这种随着缓存空间的增加带来的性能提升称为边际效益。因而,MON 有时也被称为边际效益计数器(marginal gain counter)。当然,制定动态缓存分区策略还可以使用其他方式获取所需访存信息,此处不再赘述,后文用到时再做介绍。
前文提到,基于不同的性能优化目标,制定的缓存分区策略通常有着较大区别,下面将按照不同的优化目标来分别介绍一些相关工作。
1.3.2 化吞吐量
对系统性能进行优化的一个常用指标是使得系统可以在单位时间内完成更多的工作,即化系统吞吐量。在缓存分区中,可以用总的缓存失效率或者系统IPC 作为衡量标准。
2002 年,Hsu 等人在文献中提出的缓存分区策略以化吞吐量为目标。其主要思想是:通过前述MON 可以得到各线程在前一执行阶段的缓存需求以及各线程从额外的缓存空间可以获取的边际效益。此处的边际效益指线程通过额外的缓存空间减少的缓存失效数。
定义Mi(c)为线程i 在给定缓存空间c 时产生的缓存失效数。当其可用缓存空间从c 增加至c+1 时,该线程减少的缓存失效数Gi(c)即为其所获边际效益:
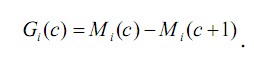
满足化吞吐量优化目标的分区策略则需要化如下表达式:

其中1 2 { , ,…, } N c c c 应该满足限制条件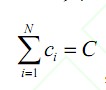 ,C 是共享缓存之和。
,C 是共享缓存之和。
通常线程的边际效益是缓存空间的单调递减函数,因而可以使用贪心算法获得的缓存分区方式:
1)初始化时,各线程分得的缓存空间ci 都为0;2)根据MON获取的上一执行阶段的访存信息,每次将单位粒度(通常按路分配)的缓存空间分给能够取得边际效益gk(ck)的线程,直至所有的缓存空间分配完毕;3)将各个MON 中的计数器清零或者将数值按一定比例减小(这种做法可以有效利用线程的过往历史信息),继续获取线程在新的执行阶段的访存信息;4)当各线程的访存特征发生显着改变时,按照步骤2)重新分配缓存空间,达到动态调整的效果。
当收益曲线不是一个单调递减函数时,贪心算法并不一定能找到理想的分区策略,可能存在短视的问题,Hsu 也在文中给出了相应的改进算法。
总的看来,Hsu 等人提出的缓存分区方案可以有效提高系统吞吐量,是很有价值的一项研究成果。
实际上,之后很多这方面的研究都是基于他们的工作成果展开的。文献中提出的MON 付出的硬件改动成本很低。然而,MON 直接从共享缓存获取各个线程的缓存命中/失效信息在很大程度上受到并行运行的其他线程的影响,不能完全准确反映一个线程独享不同缓存空间时分别应该产生的缓存失效率。
其后,Qureshi 等人在文献[4]中提出一种缓存分区策略(utility-based cache partition,UCP)。
UCP 的优化目标也是化系统吞吐量。与Hsu 对于边际效益的定义相同,UCP 中把随着缓存空间增加而减少的缓存失效数称之为收益(utility)。在UCP 中提出的收益监控器(utility monitor,UMON)针对MON 存在的缺点进行了改进,每个UMON 增加一组辅助标签目录(auxiliary tag directory,ATD)。
ATD 除了不包含具体的数据项,与共享缓存保持相同结构,仍然使用LRU 替换策略。各线程间的ATD保持独立。从而,借助UMON 获取的缓存收益信息避免了并行线程的影响,能够更为准确地反映一个线程独立的访存行为特征。
在UCP 中根据不同程序从额外的缓存空间获取的收益情况不同,可以把应用划分为3 类:当分得的缓存空间增多时,其收益不会发生显着变化的称为低收益类(low utility);随着所分配的缓存空间增加其收益显着上升的应用称为高收益类(highutility);当分配的缓存空间增加到某个临界点后其收益不再继续提升的称为饱和收益类(saturating utility)。
低收益类应用在并行运行时,彼此间对于自身可用的缓存空间不敏感,因而缓存分区并非必需的;当几个饱和收益类应用共同运行时,只要知道各应用的缓存需求,即可分别为其分配合理的缓存空间;当饱和收益类应用与低收益类应用共同运行时,优先满足饱和收益类应用的缓存需求;而高收益类的应用在与其他类应用共同运行时,由于高收益类应用总是对于可用缓存空间大小很敏感,需要特别对待。
通过对程序的访存特征进行研究并分类,解释不同的程序从缓存分区的获益状况,可以帮助制定有效的缓存分区策略。但是,UCP 中提出的分类方式更多地是对于一个线程收益曲线的直观判断,并没有提出一个形式化的算法来对程序进行准确归类。因而,很难在硬件上实现基于该分类准则对程序的归类。另外,UCP 通过在每个核的UMON 中增加ATD,以获取更为准确的访存信息,但是带来了较大的硬件开销。可以通过抽样调查线程在部分缓存中的访存行为近似估计其全局效果,例如在每个UMON 中的ATD 只保留共享缓存的奇数组(set)的标签目录,从而可以把硬件开销减半。
类似地,Lin 等人在文献中从OS 层面通过页染色对程序进行分类。在该研究中,将一个程序分别单独运行在配置为1MB 和4MB 的共享缓存系统中,并观察其运行在1MB 配置下相对于运行于4MB缓存配置时的性能降低程度,然后按其性能降低程度对程序分为4 种 以颜色命名的类。然而,因其需要将程序单独在不同缓存配置下运行多次,来得出相关分类信息,这种分类方式也很难实际用于动态缓存分区。
Xie 等人在文献中提出了一种动物分类法(animal_based taxonomy)。借助UCP 中提出的UMON 获取访存信息,按照程序的访存行为特征对线程分类,并根据分类结果制定相应缓存分区策略。
动物分类法将线程的访存行为特征与几种动物性格相对应,具体如下:
Turtles,对应于对共享缓存空间需求很低的线程;Sheep,对应只需要分配给很少的共享缓存即可达到较低的缓存失效率的线程,这类线程对于可用缓存空间大小不敏感;Rabbit,这类线程对可用的缓存空间大小敏感,但是只要分配了充足的缓存空间就可以达到较低缓存失效率;Devil,这类线程频繁发出对共享缓存的访存请求,但是无论占用多少可用缓存空间,总是会产生大量缓存失效。这类线程难以从分配到的更多缓存空间获得明显收益,并且侵略性很强,对于并行运行的其他线程有着消极影响。
动物分类法中用于对线程进行分类的指标包括:Access,一个线程对于共享缓存总的访存次数;Missessolo,一个线程独享全部共享缓存时产生的缓存失效数;MissRatesolo=Missessolo/Access,缓存失效率;WayNeededk,其中k 为一个百分数,该式表示至少需要多少路缓存才可以达到该线程独享缓存时性能的相应百分比。以上信息都可以通过UMON 获得。
针对UCP 中没有提出一个形式化的算法来对线程进行分类的缺点,文献中给出了一个具体的算法:
If (Access<1000)
Animal:=Turtle;
Else if ((MissRatesolo>10%)OR (Missessolo>4000))
Animal:=Devil;
Else if (WayNeeded95%>N/2)
Animal:=Rabbit;
Else
Animal:=Sheep.
线程只产生很少的访存请求( 例如,Access<1000),将其归类为Turtle 类;若线程即使占有全部缓存空间仍然产生大量缓存失效或者较高的缓存失效率( 例如, (MissRatesolo>10%) OR(Missessolo>4000)),则将其归类为Devil 类;当线程占有一定可用缓存空间时的性能表现即能够接近独占全部缓存空间时的性能时( 例如,WayNeeded95%>N/2),将其归类为Rabbit;否则,线程为Sheep 类。根据具体情况,还可以通过调节分类参数以取得合适的分类效果。
实际上很多情况下,过于具体的分类信息对于缓存分区并无太大帮助。重要的是要筛选出并行运行线程中侵略性强的Devil 类线程。因为这类线程会占用大量缓存空间,严重影响其他线程的性能。因此,上述算法也可以简化到只区分Devil 类和非Devil 类线程:
If ((Access>=1000) AND
((MissRatesolo>10%) OR (Missessolo>4000)))
Animal:=Devil;
Else
Animal:=Not_Devil.
当系统中不存在Devil 类线程时,可以认为线程间对共享缓存不会发生激烈争夺,因而直接采用LRU 替换策略;当存在Devil 类线程时,需要限制Devil 类线程对于系统中其他线程的影响,给其划分一块固定的可用缓存空间,其他线程共享剩余缓存。
简化后的算法复杂度和硬件开销都将大大降低,并且在线程较少时能取得较优的效果;当线程数目增多时,这种算法的效果则很难得到保证。
在文献中将线程的缓存失效分为两类:一种称为局部失效(local misses),这类缓存失效只要增加分配一路缓存,即可以变为命中状态;另一种称为全局失效(global misses),这类缓存失效需要增加分配一路以上的缓存才能由失效变为命中。
缓存分区模块监测每个线程的局部与全局失效,从而知道每一个线程的缓存需求。用CL,CL-1 分别统计单个线程在其缓存分区内LRU 和LRU-1 位置的缓存命中数;用一个计数器CG 来确定全局失效数。
将缓存分区策略的分区单位粒度设定为多2路缓存,则存在-2,-1,0,1,2 路5 种可能的分区单位。当一个线程的缓存减少或增加时,其性能损失或增益情况表示如下:

l 为性能损失函数,g 为性能增益函数,wi 和wc分别表示一个线程独占的缓存路数及系统总的缓存路数。
一个缓存分区方案所对应的总的系统性能增益为:
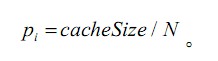
缓存分区策略需要在满足限制条件的前提下化G.这种算法是一种穷举的做法,需要列出所有的分区可能性并进行比较,在系统线程数目较少的情况下可以取得很好的效果;随着线程增加将发生状态空间的爆炸。
1.3.3 公平性
系统的性能好坏不止与吞吐量相关,公平性也是一个重要的衡量指标。前述研究的优化目标都主要集中于化系统吞吐量而忽略了公平性。这可能导致系统中某些线程的访存请求长时间得不到服务乃至饿死的情况发生,对该线程的性能造成影响,进而也会影响到系统的性能。本节的研究主要着眼于系统的公平性,以达到同时改善所有线程性能的目的。
Kim 等人在文献中从改善系统公平性的角度对缓存分区进行了研究。实验证明,以改善系统公平性为优化目标的缓存分区策略通常可以同时提高系统吞吐量,但是以化吞吐量为目标的缓存分区策略则对无法保障公平性。
该项研究首先对系统的公平性给出一个理想化的定义如下:
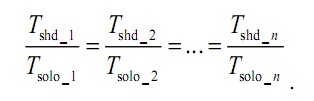
Tsolo_i 表示线程i 独占全部共享资源时所需的执行时间;Tshd_i 表示多个线程并行运行时执行线程i所需的时间;当所有线程在并行环境下的执行时间按相等比例增长时,则认为系统是公平的。存在如下表达式:
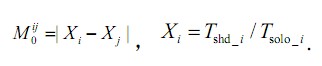
Xi 表示线程i 在与其他线程协同运行时相对于它独自运行时的减速比(slowdown); 0ij M 表示系统中任意两个线程间减速比之差。0ij M 越小,表示两个线程性能所受到的影响程度越相近。因此,一个追求公平性的缓存分区策略,应该使得0ij M 之和化,则系统的公平性程度。
在实际并行系统中,Tshd_i 信息易于获取,但是Tsolo_i 的相关信息很难取得。因此,需要寻找可以替代执行时间T 同时又易于获取的指标。
Kim 等人在文献中另外提出了5 项可用的指标来衡量系统公平性。需要用到的信息包括各线程独享缓存时产生的缓存失效数Missessolo 和缓存失效率MissRatesolo,以及多个线程并行运行时的缓存失效率Missesshd 和缓存失效率MissRateshd.对于任意一对线程i 和j,5 项指标分别如下:
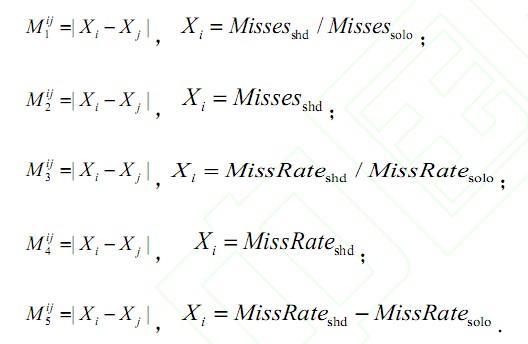
这里提出的几个指标都具有较为直观的意义:
M1 用于平衡各线程缓存失效数增加的比例,M2 则是平衡各线程的缓存失效数;类似的,M3 用于平衡各线程缓存失效率增加的比例,M4 平衡各线程的缓存失效率;而M5 则用于平衡各线程由于协同运行增加的缓存失效率。
在确定了系统公平性的衡量指标后,需要制定相应的缓存分区算法, 通过化表达式表达式1
的值来化系统公平性程度。文献中提出的缓存分区算法由3 部分操作组成:初始化( initialization ), 回滚( rollback ) 和重分区(reparationing)。
初始化操作,将共享缓存平均分配给各个线程,
回滚操作,每一个时间段t 结束时:
1)将可能需要重分配的线程初始化为待调整线程集CS={1,2,…,n}.
2)对于每个线程i 检测其是否在刚刚结束的时间段t 中通过重分区操作获取了更多的缓存分区Aij(Aij 表示线程i 通过重分区操作从线程j 得到的缓存空间),用集合AS 来记录所有时间段t 中进行的缓存重分配,如果时间段t 的分区策略没有取得预期效果,即:
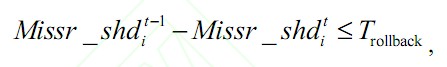
则进行回滚操作,返回重分区之前的状态并且将线程i,j 从待调整线程集CS 中剔除:
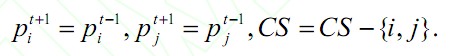
重分区操作,在每个时间段t 结束并且回滚操作完成之后进行:
1)初始化重分配集AS={};
2)对于每个线程i∈CS,按照选定的衡量指标计算其公平性ti X ;
3)根据ti X 值排序,分别找出imax∈CS 以及imin∈CS;
4)若max_i min_i repartition X ? X ?T,则进行重分区:

这个缓存分区算法本质上是用性能受影响线程的部分缓存空间来补偿性能受影响的线程,从而提高系统公平性;回滚操作可以避免将缓存分配给收益很小的线程,从而提高了缓存利用率。
实验结果还表明,采用不同的公平性衡量指标制定的分区策略所取得的效果是不一样的,其中采用M1取得的效果,其次为M3,效果差的则是M2.
上述方案是通过底层硬件来实现系统公平性。
之后Rafique 在文献中还从操作系统层面实现了上述缓存分区策略,并以M4 为衡量标准,取得类似的优化效果。
另外,对于前面提到的Tsolo_i 信息难以获取的问题,我们可以通过增加一组计数器,来记录每个线程由于其共享缓存中的数据被其他线程替换掉而产生的额外延迟Tdelay_i,用Tshd_i 减去Tdelay_i 则可以求出Tsolo_i,从而能够更准确地衡量公平性。
1.3.4 细粒度缓存分区
前面介绍的缓存分区分区策略,普遍存在的一个问题是缓存分区粒度较大。缓存的路数与其关联度(associativity)相关。通过增加缓存路数能够有效提高缓存关联度,从而降低冲突带来的缓存失效,但同时也会增加命中延迟和功耗。因此,缓存设计需要对各类代价进行折衷考虑,能够维护的缓存路数总是一定的,不能随意增加。在线程较少而缓存路数较多时,按路分区可以近似取得理想的分区效果;随着线程数的增多,每个线程的平均可用缓存路数大大减少,按路分区的方式则不再可取。
缓存分区粒度过大还不可避免地会带来缓存空间的浪费。例如一个线程分配到四路缓存,但是其中可能有一部分缓存空间的复用率很低或者根本就没用到,则该线程分到的缓存空间存在冗余,得不到充分利用;与此同时,另一些线程的缓存需求可能无法得到满足,却无法使用其他线程的冗余缓存空间。
Xie 等人在文献[10]中提出一种新的缓存管理策略称为提升/ 插入伪分区策略(promotion/insertion pseudo-partitioning ,PIPP)。PIPP 结合UCP 的缓存分区策略思想,区别在于对缓存并不进行明确的严格分区,而是通过管理缓存的替换优先级和插入策略来达到与缓存分区类似的效果。插入策略根据确定好的替换优先级选择应该被逐出的缓存行;提升策略根据缓存命中情况更改缓存的替换优先级。给缓存行设定不同替换优先级实现类似缓存分区的效果。PIPP 没有实际对缓存进行分区,因而,制定好分区策略后,线程在需要的时候仍然可以借用其他线程的冗余缓存空间。PIPP 允许从其他线程借用缓存空间在避免缓存空间浪费,提高缓存利用率的同时,却难以防止某些侵略性较强的线程可能过多占用其他线程缓存空间,导致这些线程的性能受到严重影响的隐患。另外,PIPP 是针对UCP 策略的缓存分区粒度过大而提出的,对于其他的调度策略可能并不适用,可扩展性较差。
前面提到,缓存的关联度与路数相关。但是在缓存分区中,若每个线程只能使用其中部分路的缓存,则会破坏缓存的这种关联度,导致由冲突带来的缓存失效率上升。Sanchez 等在文献中提出的zcache,通过解除缓存路数与关联度之间的耦合关系,使得缓存的关联度远高于实际的物理路数(例如,一个实际只有4 路组相联的缓存可以取得类似64 路缓存的关联度)。这种方法在提高关联度的同时,也从逻辑上增加了缓存的路数,减小了分区粒度。
在此基础上,Sanchez 等进一步在文献中针对之前的UCP 策略分区粒度大、可扩展性差、效率低的问题,提出缓存分区策略Vantage,可以有效克服上述缺点。Vantage 以缓存行为单位进行缓存分区,解决了分区粒度大的问题;Vantage 以较小的代价把共享缓存分为数十个分区,解决了随着线程数增多缓存分区可扩展性差的问题;同时在Vantage 中,不会破坏缓存的关联度,避免由于缓存关联度降低导致的缓存失效;并且线程间仍然执行严格分区,杜绝线程间的相互干扰。与之前的缓存分区方案的另外一个不同点在于,Vantage 中并不会把全部共享缓存空间分配给所有的线程,而是保留一小部分(例如,10%的缓存空间)。当线程对于缓存的实际需求超出缓存分区策略分配给该线程的缓存空间时,可以共用保留的这部分共享缓存,而不是占用其他线程的缓存空间。
责任编辑:
【免责声明】
1、本文内容、数据、图表等来源于网络引用或其他公开资料,版权归属原作者、原发表出处。若版权所有方对本文的引用持有异议,请联系拍明芯城(marketing@iczoom.com),本方将及时处理。
2、本文的引用仅供读者交流学习使用,不涉及商业目的。
3、本文内容仅代表作者观点,拍明芯城不对内容的准确性、可靠性或完整性提供明示或暗示的保证。读者阅读本文后做出的决定或行为,是基于自主意愿和独立判断做出的,请读者明确相关结果。
4、如需转载本方拥有版权的文章,请联系拍明芯城(marketing@iczoom.com)注明“转载原因”。未经允许私自转载拍明芯城将保留追究其法律责任的权利。
拍明芯城拥有对此声明的最终解释权。
相关资讯
:
基于MC33771主控芯片的新能源锂电池管理系统解决方案

AMIC110 32位Sitara ARM MCU开发方案

基于AMIC110多协议可编程工业通信处理器的32位Sitara ARM MCU开发方案
基于展讯SC9820超低成本LTE芯片平台的儿童智能手表解决方案

基于TI公司的AM437x双照相机参考设计
基于MTK6580芯片的W2智能手表解决方案









 2012- 2022 拍明芯城ICZOOM.com 版权所有 客服热线:400-693-8369 (9:00-18:00)
2012- 2022 拍明芯城ICZOOM.com 版权所有 客服热线:400-693-8369 (9:00-18:00)


