



 产品分类
产品分类
基于Altera公司CYCLONEII芯片EP2C35-672 FPGA实现CRC循环冗余校验的自定义指令设计方案
 29
29
 拍明
拍明
原标题:基于EP2C35-672 FPGA实现CRC循环冗余校验的自定义指令设计方案
通信系统中,为确保数据传输和存储的可靠性,引入了信道编码。一是可使得编码后的码流频谱适应信道频率特性,二是可检测并纠正传输中的误码。前者属于谱成形技术,后者属于差错控制技术。循环冗余校验(CRC)属于后者,它是通过增加冗余信息,达到发现误码的目的。CRC校验由于检错能力强,被广泛用于各种数据校验中。
可编程片上系统(SOPC)是一种特殊的嵌入式系统,它可将处理器、存储器、外设接口和多层次用户电路等系统设计需要的功能模块集成到一块芯片上。NiosII是Altera公司的SOPC解决方案,是一个运行在FPGA上的32位RSIC处理器。NiosII系列软核处理器最大的特点之一是可灵活地增加用户指令,可以把系统中用软件处理耗时多的关键算法用硬件逻辑电路来实现,大大提高系统的效率。
本设计即是采用Altera公司的CYCLONEII芯片EP2C35-672FPGA,依靠NiosII软核和硬件逻辑结合的速度优势,实现基于NiosII的HDLC协议控制系统中CRC循环冗余校验的自定义指令实现。
1循环冗余校验CRC
循环冗余校验码检错能力强。校验的基本思想是利用线性编码理论,在发送端根据传送的k位二进制码序列,以一定的规则产生(n-k)位校验监督码,并附在信息码后,构成一个n位的二进制码序列来发送,如图1。接收端则对收到的信息采用和发端相同的算法进行校验,若有错,发端重新发送数据。

图1加入CRC校验的码序列
CRC校验的编码原理:
(1)首先将待发送数据序列D(x)乘以Xk,其中k为生成多项式G(x)的最高次幂;
(2)将乘得的结果Xk•D(x)用生成多项式G(x)去除;
(3)忽略其商,仅将其余数R(x)取出,并与Xk•D(x)相加,形成n位输出码数据序列D′(x),即:D′(x)=Xk•D(x)+R(x);
最终得到的余式R(x)即为CRC校验码。它跟在信息码后一并发往信道。
常见的生成多项式有:

对不同的类型,CRC的检错能力是有差异的。冗余位越多,检错能力越强,但实现起来就会相对复杂,并且占用的开销也会增大。实际中,总是基于产品的应用领域综合考虑来做出最合适的选择。
2CRC校验的自定义指令实现
2.1自定义指令
自定义指令就是用户让NiosII软核完成的功能,功能由电路模块来实现,电路模块用硬件描述语言(HDL)描述,连接到NiosII软核的算术逻辑部件上,如图2。这样,用户指令就可以把系统中用软件处理耗时多的关键算法用硬件逻辑电路来实现。NiosII处理器支持256个具有固定或可变时钟周期操作的定制指令,允许设计人员利用扩展CPU指令集,通过提升那些对时间敏感的应用软件的运行速度,来提高系统性能。

图2定制指令逻辑连接到NiosII的ALU
2.2CRC算法研究
(1)串行实现法
串行算法实现原理比较简单,如图3。只需要移位寄存器和异或门这些基本的逻辑器件,所以很适合硬件电路。但是串行法一个时钟周期只能计算一位数据,只适用于数据串行传输的场合,接入并行处理的CPU时会大大降低效率。

图3CRC串行算法原理图
(2)并行计算法
并行算法可以在一个时钟内对多位数据进行编码,提高计算速度。信息码一次并行输入,经过必要的处理时间即可输出编码结果,大大缩短了处理时间,具有很大的优越性。目前采用的CRC并行算法有查表法等,这些方法有一定的优势,但也有缺点。本设计所采取的是并行计算法,不仅保持了并行算法的优势,而且还克服了查表法的缺点。
◆与查表法比较,这种方法消除了查表法所必须的CRC余数表,减少了资源占用,降低了成本。不再需要存放余数表的高速存储器,减少了时延,提高了计算速度。
◆可以全部用FPGA的内部资源实现,总的输出时延为两级异或门时延和寄存器的锁存时延之和,约为5-10ns,而查表法的总时延达到了100ns,因此计算法可以用于处理时钟速率很高的场合。
◆查表法的并行度局限于8位。而计算法可以灵活地实现各种并行度的CRC计算。由于可以采用更大的并行度(如32位并行计算,甚至64位的并行计算),因此降低了处理时钟周期,并且与CPU的接入也更加方便。
总之,这种并行实现方式适用于各种数据宽度CRC校验,而且随着并行输入数据宽度的加宽,运算速度也加快。它的缺点:由于并行计算是通过多级反馈实现的,故复杂的反馈组合电路会带来较大的门延迟,但QuartusII开发环境通过优化组合电路的结构,可以很大程度上降低延迟,使电路适用于较高的时钟频率。
并行计算法的具体原理推导如下:
设
![]()
为第i个数据移位j次后寄存器的最终状态,
![]()
为第i个数据移位j次后寄存器的状态,
![]()
为输入数据的第j个数据,
![]()
为生成多项式的第i位数值,j的取值范围由一次可校验的总数据位数决定,k为生成多项式的最高次幂,这里,j=0、1、2……32,k为16。其递推公式为:
![]()
并且令
![]()
;按照递推公式对移位寄存器的每一位进行计算,直到j=0,此次计算才结束,所有值都计算完毕后,得到中间结果:

,其中
![]()
为0或1;由于输入数据的高低位与寄存器高低位相反,因此需再进行一次倒排序才可得到正确的输出数据:

,即得到了这组数据最终的CRC运算结果。
2.3CRC算法的VHDL实现
据上述原理推算了32位并行数据CRC异或逻辑关系,并用VHDL实现了并行CRC算法,添加到NiosII配置表中形成自定义指令,在C程序中通过函数调用就能以很高的速率完成复杂的CRC运算,极大地提高了系统的效率。
图4为CRC并行计算法的仿真结果。

图4CRC并行算法仿真结果
2.4使用NiosII的自定义指令提高系统性能
CRC校验算法需要大量的逻辑运算,如果用软件实现要占很多个时钟周期,系统的效率降低,而用硬件完成则仅需几个时钟周期。
定制指令逻辑和NiosII的连接在SOPC++Builder中完成。NiosIICPU配置向导提供了一个可添加256条定制指令的图形用户界面,在该界面中导入设计文件,设置定制指令名,并分配定制指令所需的CPU时钟周期数目。系统生成时,NiosIIIDE为每条用户指令产生一个在系统头文件中定义的宏,可以在C(或C++)应用程序代码中直接调用这个宏。表1为NiosII软件实现CRC算法和自定义指令实现性能对比。
表1NiosII软件实现CRC算法和自定义指令实现性能对比

可见,对于2字节数据,自定义指令的运算速度是软件法的2~10倍,且使用的资源大大降低。表1中的自定义指令是对16位数据而言的。我们所采用的帧结构,数据段有2字节,控制段1字节,地址段1字节,因此CRC计算时采用32位。从仿真图4中可以看到,从输入数据到计算完成用了7~8ns,而工作频率50MHz的NiosII系统一个时钟周期为20ns。这样,完全可以在一个周期内完成计算,加上装载及返回时所需的额外周期,根据表1的数据进行近似的线性分析,可知最终一次CRC校验需要16~20个周期,比软件法提高了4~40倍,大大提高了系统处理的速度。
3结语
CRC校验由于检错能力强,被广泛应用在各种数据校验中。本文研究了CRC并行算法,并且通过增加自定义指令的方法,把用软件处理耗时多的CRC校验算法在NiosII系统中用硬件逻辑电路来实现,极大提高了系统的效率。实验结果也表明了该方法的优势。
责任编辑:David
【免责声明】
1、本文内容、数据、图表等来源于网络引用或其他公开资料,版权归属原作者、原发表出处。若版权所有方对本文的引用持有异议,请联系拍明芯城(marketing@iczoom.com),本方将及时处理。
2、本文的引用仅供读者交流学习使用,不涉及商业目的。
3、本文内容仅代表作者观点,拍明芯城不对内容的准确性、可靠性或完整性提供明示或暗示的保证。读者阅读本文后做出的决定或行为,是基于自主意愿和独立判断做出的,请读者明确相关结果。
4、如需转载本方拥有版权的文章,请联系拍明芯城(marketing@iczoom.com)注明“转载原因”。未经允许私自转载拍明芯城将保留追究其法律责任的权利。
拍明芯城拥有对此声明的最终解释权。
相关资讯
:
基于MC33771主控芯片的新能源锂电池管理系统解决方案

AMIC110 32位Sitara ARM MCU开发方案

基于AMIC110多协议可编程工业通信处理器的32位Sitara ARM MCU开发方案
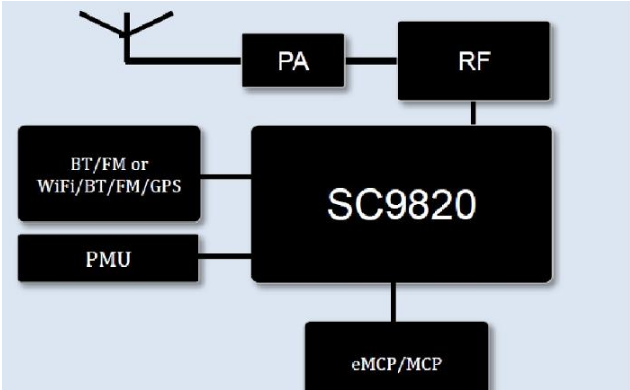
基于展讯SC9820超低成本LTE芯片平台的儿童智能手表解决方案

基于TI公司的AM437x双照相机参考设计
基于MTK6580芯片的W2智能手表解决方案









 2012- 2022 拍明芯城ICZOOM.com 版权所有 客服热线:400-693-8369 (9:00-18:00)
2012- 2022 拍明芯城ICZOOM.com 版权所有 客服热线:400-693-8369 (9:00-18:00)


